
開発:そもそもshellを作ろうと思い立ったのは昨日の朝、UDPでならどの程度のデータ転送速度が実現できるか興味を持ったためです。でついつい、Cでゼロからプログラムを書き始めてしまったのですが、しばらくして、いやいやこんな力仕事的な書き方はもう卒業すべきだと思い、Goに立ち返ったのでした。
開発:で、ソケットを作ったり繋いだりするのはGoのパッケージを使えば簡単に書けるわけです。まあ、ライブラリがあればどんな言語だって簡単ですけど。しかも、Goで使うべき関数を間違えてしばらく戸惑いました。システム関係のパッケージのドキュメントはどうも完成度が低い気がします。まあともかく、やってみた結果がこれです。

基盤:2.27GB/s!
開発:もちろんUDPですから、データは取りこぼすわけです。ですが、同一マシン内で、マシンの負荷が軽ければ、ほぼ受け取れます。この例では 99.7%は受け取れています。
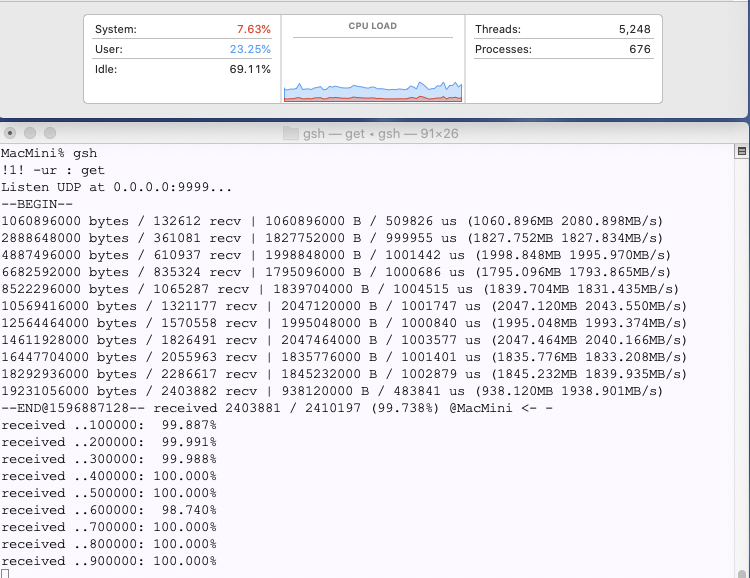
基盤:このMacMiniがこれまで生きてきて一番高速なネットワーク転送です。
社長:使用しているメモリ2.7GHzですからね。まあおそらく64bit、8バイト/クロックでアクセスできるんでしょうけど。いや、32ビットかな?

開発:32ビット4バイトだったとすると4 x 2.7 で 10.8GB/s、64ビット8バイトだとすると21.6GB/s は出るはずですね。
基盤:172.8Gbps。
社長:メモリのコピーでは読んで書くから、その半分になる。だからメモリのコピーは最速で10GB/sと思います。
開発:ただ、CPUの命令ループでコピーする場合、1ワードのコピーにCPUクロックが複数かかりますね。ソースとディスティネーションのポインタレジスタの更新、終了判定、あとはロードとストアと、結局8バイトのコピーに8クロックくらいかかると思うんです。簡単なテストプログラムを書いて測りました。volatile にした 100MBのバッファの間をでコピーを10回繰り返すというものです。

基盤:理論値の10GB/s出てますね。
社長:ユーザからDMAは使えないんですかね?
開発:さあ。このmemcpyの値は、異常に速かったり遅かったりします。デュアルポートメモリでも無いでしょうに18GB/s出ているのも謎です。他のCPUループでの実装はほぼ安定していますので、ひょっとしてDMAを使っているのかも知れません。デバイスとして使えるんでしょうか。システムコールで叩いてるんでしょうか?
基盤:通信経由のコピーがプロセス内でのメモリーメモリコピーと同等というのはびっくりですね。
開発:それも実際にはDMAによるメモリーメモリコピーに帰着させてるんじゃないかとは思いますけどね。他のマシンへの転送では、数マイクロ秒間隔を開けてやらないと、OSのバッファがいっぱいになってエラーが出るのですが、同一マシン内だとそれが出ないんです。
社長:自分自身に送信してコピーすると高速化したりするかもですねw
* * *
開発:それで、次はTCPではどうなのかといことになります。やってみた結果がこれ。
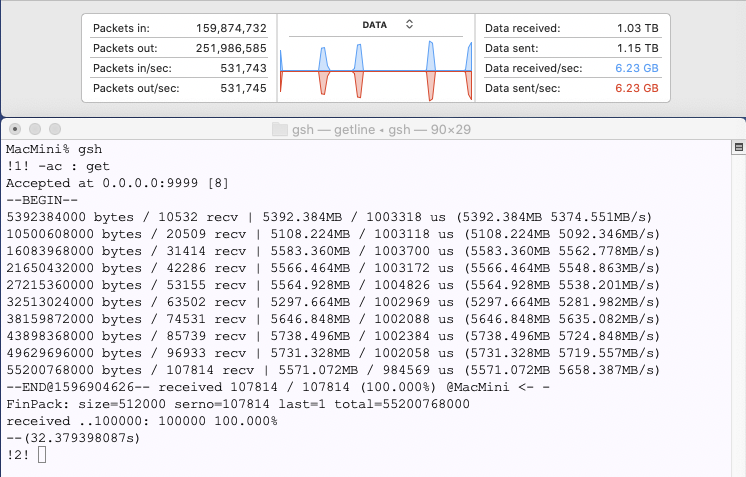
基盤:ネットが6.23Gbpsに到達しております!
開発:このMacMiniは、外に対しては1GB/sでしか繋がりませんが、内部的には違う話ですね。プロセス間での通信は、プロセス内部でのメモリのコピーと同等の性能が出ていると見えます。
社長:TCPのほうが速いんですね。
開発:UDPだと固定長パケットで、8KBを超えると起こられてしまうわけです。だから送信の回数、OSとの通信が多くなります。一方TCPではそういう制約は無いですから、でっかいバッファのありかをどーんとOSに教えてやって任せればよいわけです。200KB程度のサイズまでは、サイズが大きいほど速くなります。
基盤:ただこれは、同一マシン内での通信の特殊状況なんでしょうね。
開発:そうですね。ping への RTT が 0.05ms とかいう世界です。これが、隣のマシンになると 0.5ms程度はどうしてもかかる。さらにWANに出ると速くても5ms程度はかかる。アジア近隣で50ms、アメリカまで行くと130ms、ヨーロッパまで行くと250msになってしまうわけです。相手の受信確認を頻繁に行うTCPではこれは、まるで別の世界になってしまいます。
* * *
開発:されそれで、RTT 0.5ms程度の隣のマシンとの転送ですが、sendのサイズは1500バイトで十分に1Gbpsを使い切ることがわかりました。
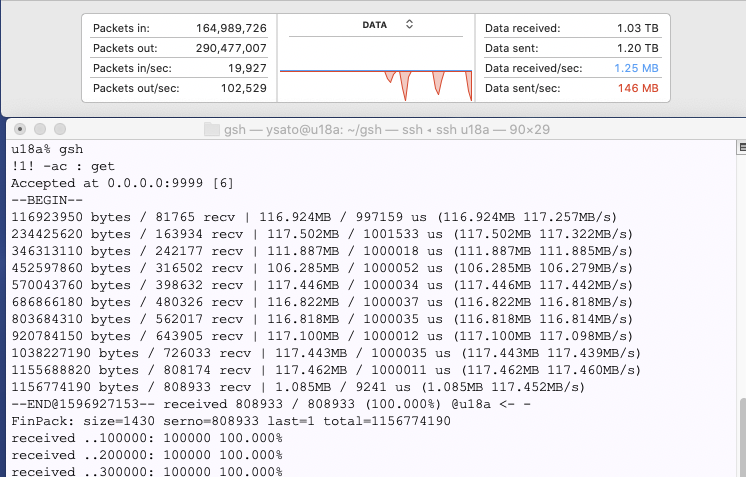
開発:一方UDPの成績は芳しくありません。どうも性能が出ない…
* * *
開発:えーと、調整をした結果、まずまずの性能に落ち着きました。
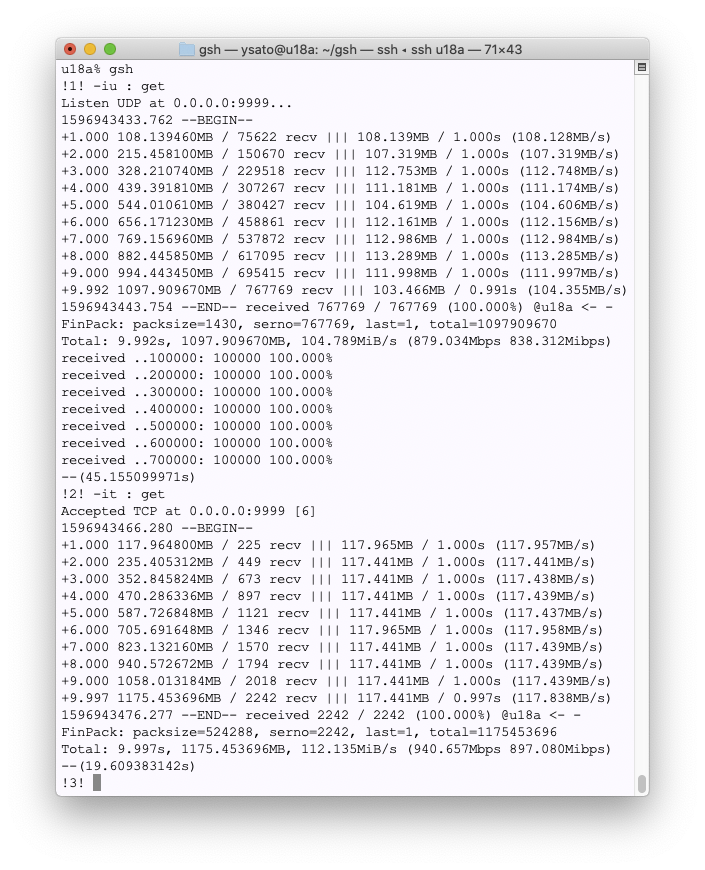
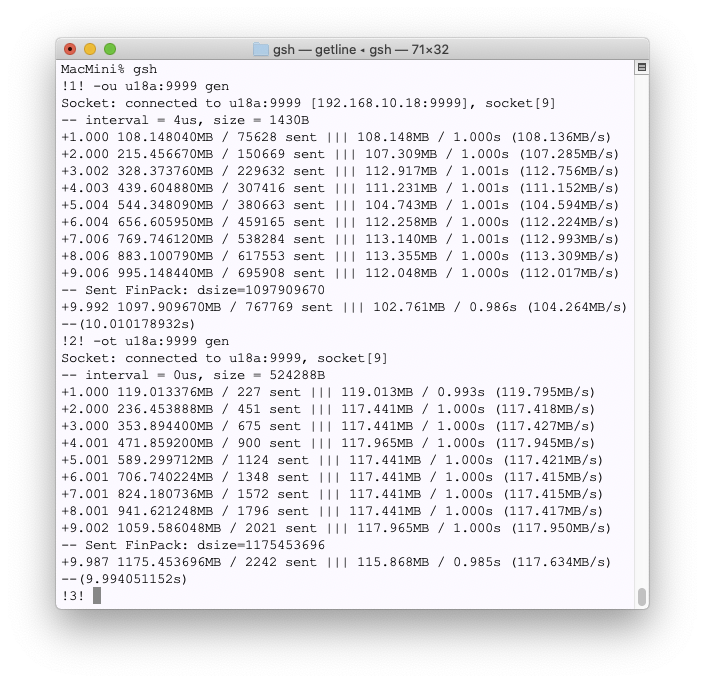
開発:ペイロードぶんのスピードとして TCPでは 940Mbps出ていますので、理論上の最高性能かなと思います。一方UDPでは 880Mbps程度。連続して送るとシステムのバッファが溢れてしまうので、4マイクロ間隔で1430Bを送っています。これだと、バッファがいっぱいだよエラーが出ませんし、受け側もほぼ100%受け取れます。これ以上間隔を短くすると、送り側としてはTCP並の速度で送れますが、受け側がボロボロになります。
開発:ああ、でも3usなら送信側が再試行すれば100%受け取られますね。



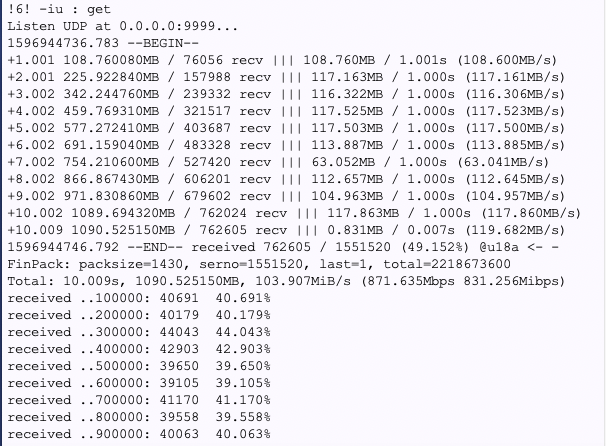
基盤:ぼろぼろですねw
社長:要するにLANというかレイテンシーがサブミリ秒の近接したノード間でUDPを使うメリットは無いということですね。
開発:そう思います。で、問題はレイテンシーが大きい時はどうか、ということで、本題になります。なお、この実験は電力を約60W食うことが観測されています(笑)
* * *
開発:まあこれは実は最初にやって結果はわかっていまして、比較のためにマシン内や近接マシンで試すのに時間をとられてしまいました。
開発:ではまずは最果ての地、ドイツフランクフルト支所。RTT 250ms 超です。ここはscpのアップロードで1MB/sしか出ないことがわかっています。このベンチマークでもTCPでのデータ送信は同様な結果になります。
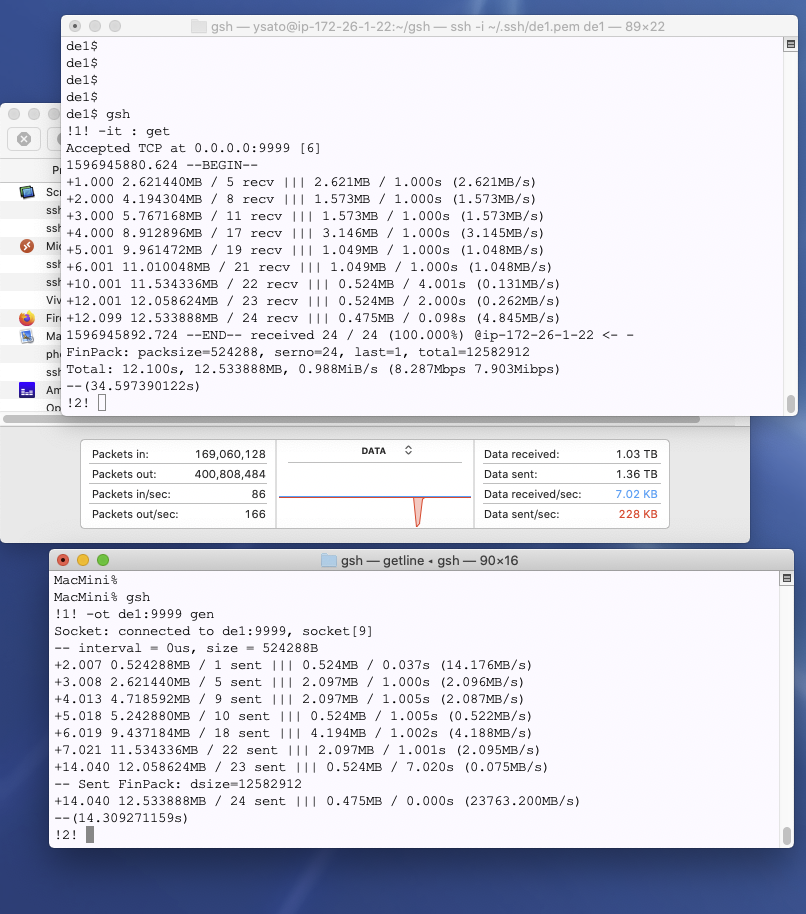
基盤:しかもスピードが時々刻々かわっている。ネットの状況に左右されてるんでしょうね。遠隔との通信の速度は、非常に不安定であることは実感としてわかっています。
開発:そしていよいよ、UDPではどうか。
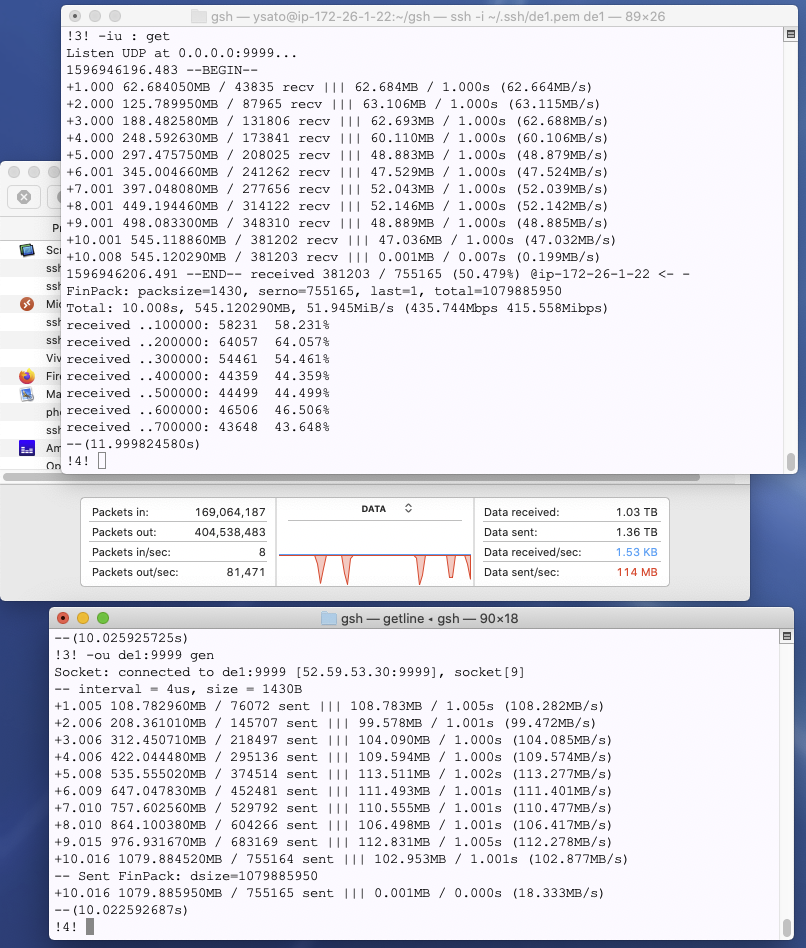
基盤:50MB/s で届いていますね!50倍速!
開発:まあ、半分落ちてますけどね。
社長:といいますか、我社から社外に向けて実際にギガビットでデータを送出したのはこれが初めてですね。
開発:それでこの数値は、相手がドイツでも東京でも大差無いんですよ。つまり、うちのインターネットは、上りは500Mbpsしか出ないのではないかという気もします。
社長:ライトセール以外の相手にためしてみたいところですが。CPU負荷的に厳しいとか。
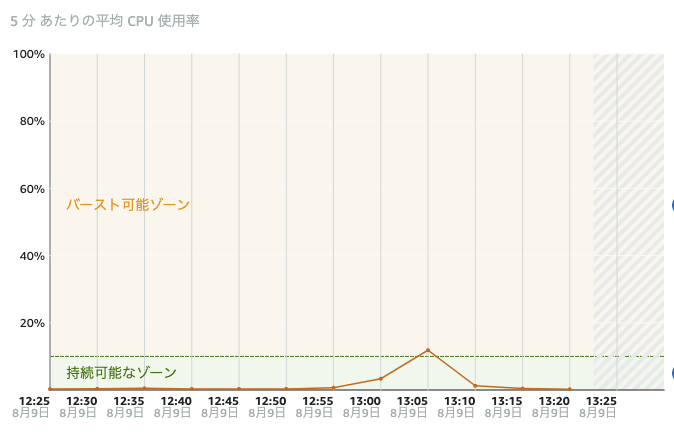
開発:全般的には余裕ですね。30%食うことはないです。なにせデータを受けるだけで何も処理してませんし。
開発:たとえばライトセール東京にある我社ネームサーバ。
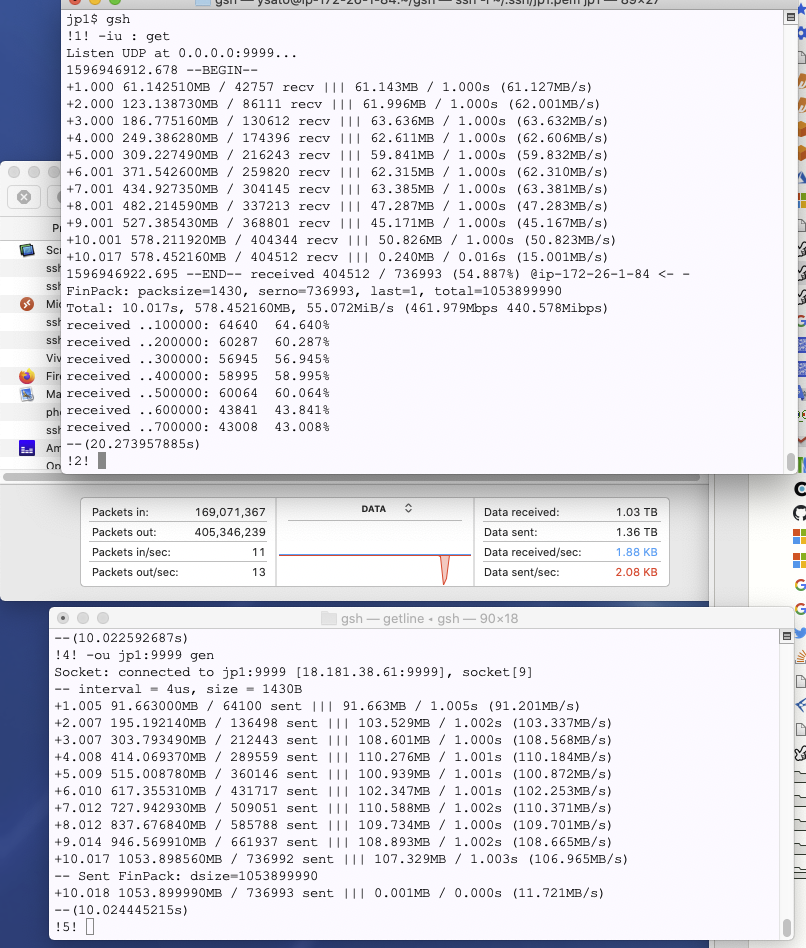
開発:もともとパケットがロスするのは織り込み済みですから、到達してないパケットのマップを返してもらって再送すればよいわけですが、ではどのくらいの速度までロスが起こらないかをためしてみす。… … 6.28MiB/s、50Mbps までは大丈夫っぽいですね。

開発:161マイクロ秒間隔での送信です。
社長:刻みましたねw
開発:普通のデータは1ビットでも落ちたらいけませんが、画像とかはとりあえず届いたものから表示するとか、ありますよね。動画だったらなんだか画質が落ちるとか。
社長:これはそもそも、差分だけ送るという方法に相性が良いですね。rsync とはちょっと違う方向性を考えると面白いかも。
基盤:ところで我社の$5ライトセールは2TB/月という制約ですが、どういうふうにリミットしているんでしょう?もうけっこう上限のような。
開発:ドイツ支部は暇だし死んでも大丈夫ですw でも、テスト用のインスタンスを作ってやってみますかね。
経理:まさか、上限を超えたぶんは従量課金になるとかではないですよね…
-- 2020-0809 SatoxITS